Direct-to-consumer genetic testing
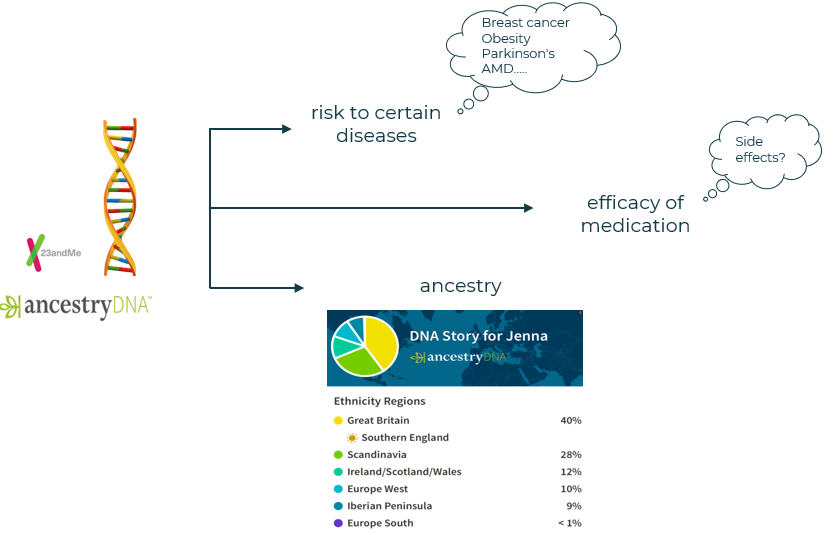
Genetic testing is a medical test to know about certain things of a person like their disease traits, risk to certain diseases, how effective a drug will be on their body etc. from their DNA samples. Historically, genetic testing is done through healthcare providers. But with the rise of direct-to-consumer genetic testing companies, these genetic tests are marketed directly to the customers. So now the customers can buy these tests at store or online, upload their DNA samples and know their genetic traits and also their ancestry. With a rise of such direct-to-consumer companies, over 20 million people have uploaded their DNA profiles online till date.
But, what else can be done with your DNA profile?

In 2018, US police tracked down a heinous suspect called the Golden State Killer after a decade of killing 12 people and raping 45 women, by matching the DNA found in crime scene with the DNA profiles uploaded by people in the public websites. Although, the killer’s DNA was not there in the database, his DNA matched with one of the other DNA profiles in there, which turned out to be a distant family member of the killer. Although, in this case it helped the police find a suspect, it also shows how much exposed we can be to the parties of interests if they can get a hold of our publicly available data.
Not only that, it turns out that there are a lot of other things which can be inferred from DNA profile like your height, weight, body mass index, voice, age, sex, eye color, skin color. But even worse, in 2017, Lippert and his team were successful to reconstruct 3D facial structures of people from their DNA profiles. In the figure below you can see how close some of the reconstructions were to the real images.

Your data is your digital footprint.
- Your digital footprint refers to all the personal data and information available about you online.
- Your active digital footprint includes your emails, social media interactions, and other messages with your name attached.
- Your passive digital footprint is information you unintentionally leave behind, like your IP address, cookies, geolocation data when you use maps etc.
But these are public data, why should you care?
Well, there are many companies who do care. Also, we don’t even know how our digital footprint can be used against us. Let’s consider the following scenarios.
- What if our medical data ended up in the hands of health insurance companies that could misuse it to charge us accordingly?
- What if our DNA data gave away the possibility of developing a disability in future that would limit our access to the job market or to certain professions?
- What if instead of helping fight criminals, it creates discrimination or bias against a community, race or religion?
All these are questions we don’t know answer to yet, but we can already see many cases where these type of discriminations are taking place.
What if the dataset is made anonymous?
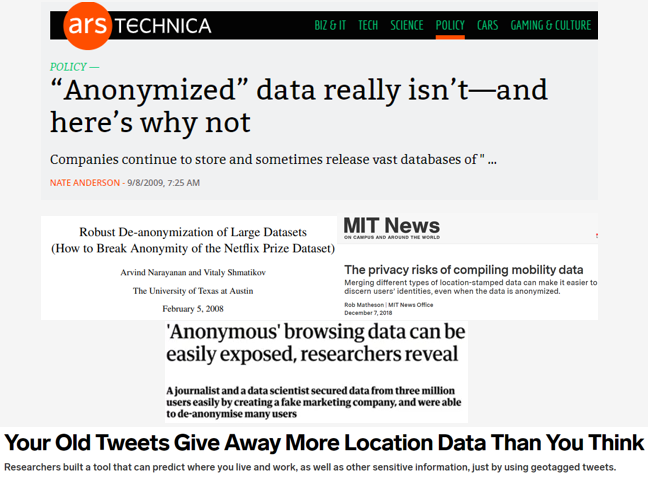
Why can’t we just remove the identifying information from datasets like name, ID or other unique information? It turns out that this type of data anonymization is not enough to prevent companies from tracking you. The reason is linkage attack.
Linkage Attack
It is very much likely that there are multiple different types of data of the same individual available on the internet. Even if the obvious information is removed, it is not too hard to combine the original data with other accessible data sources in order to uniquely identify an individual and learn private or sensitive information about that person. One of the first people to demonstrate this was Latanya Sweeney. In 2002, she showed how she could link a publicly available anonymized data of hospital visits to another totally anonymized public data of US voting registrar (Source).
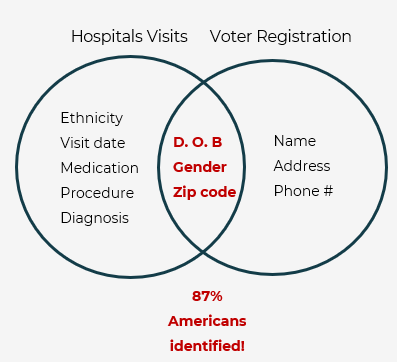
By linking these databases by the date of birth, zip code and gender, she could successfully identify 87% of the US population and retrieve their medical history!
Unfortunately, this is not the only successful case of data de-anonymization. There are a lot of other famous cases where individual people had been traced back by combining their scrambled and apparently harmless digital footprint.
In this digital era, no data is useless and once your is out to the web, it is going to be there forever. These data will somehow link back to you at some point, without you even realize. Therefore, let’s choose wisely what information about ourselves we want to make public. But in a world where our lives are completely tied to our smart devices, it is literally impossible to prevent sharing our data. More importantly, as an exchange to our data being collected by service providers, we are being able to enjoy highly customized services like targeted ads, recommendations based on our preference, finding an old friend from schools and many more. We might think that it is a deliberate “choice” we must make in order to enjoy these advanced AI-powered services. However, be assured that it is not the case at all. We do not have to make a choice of sacrificing our privacy and data. There are technologies which are capable of building AI-powered products using data without having to access, see or store them. These set of techniques are called privacy-preserving AI techniques.
Privacy-preserving AI techniques
Privacy-preserving AI is the art of performing data science and build AI solutions by training or querying on data without the need to collect, distribute or even look at them. This is a very active research area at the moment. Big companies like Google and Apple are already adopting such techniques. Below is the list of some of the major privacy-preserving AI tools.
- Federated Learning
- Differential Privacy
- Homomorphic Encryption
- Secure multi-party computation (SMPC)
More on these techniques and their mechanisms will be available in the upcoming blogs. Stay tuned!
In the meantime, listen to my talk on Privacy-Preserving AI on Women Who Code – CONNECT Reimagine Global Conference.